TryHackMe security Footage writeup (zh-TW)

題目資訊
- 平台: TryHackMe
- 房間名稱: Security Footage
- 難度: Medium
- 目標: 從網路封包中恢復攝像頭錄像
- 檔案:
security-footage-1648933966395.pcap - 連結: https://tryhackme.com/room/securityfootage
Step 1: 協議分析 - 理解流量結構
為什麼先查看協議統計?
在取證中,為了了解數據的整體結構,不要盲目地逐個封包查看,應該先從宏觀角度分析:
- 有哪些協議?
- 流量分佈如何?
- 有沒有異常或關鍵協議?
執行協議層次統計
tshark -r security-footage-1648933966395.pcap -q -z io,phs
結果分析
Protocol Hierarchy Statistics
eth frames:1109 bytes:6023125
ip frames:1109 bytes:6023125
tcp frames:1109 bytes:6023125
http frames:1 bytes:402
關鍵發現 🔍
- 總共 1109 個封包,約 6 MB 數據
- 全部是 TCP 流量 - 沒有 UDP
- 只有 1 個 HTTP 封包 ⭐ - 這是最關鍵的線索!
為什麼立刻鎖定 HTTP?
在網路取證中,HTTP 封包通常包含:
- 請求/回應的元數據(URL、Content-Type、檔案大小等)
- 通訊的起點 - 後續的大量 TCP 流量很可能是 HTTP 回應的數據部分
檔案名稱是 security-footage(監控錄像),結合:
- 大量 TCP 流量(6 MB)
- 只有 1 個 HTTP 封包
推論:這個 HTTP 封包發起了請求,伺服器透過 TCP 流回傳了影片數據!
Step 2: HTTP 封包深度分析
查看 HTTP 封包詳細內容
tshark -r security-footage-1648933966395.pcap -Y "http" -V
關鍵資訊提取
GET / HTTP/1.1
Host: 192.168.1.100:8081
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:98.0) Gecko/20100101 Firefox/98.0
Source: 10.0.2.15
Destination: 192.168.1.100
Source Port: 42312
Destination Port: 8081
TCP Stream: 0
分析結論
- 這是 HTTP GET 請求 - 客戶端向攝像頭請求影片
- TCP Stream 0 - 所有通訊在同一個 TCP 連線中
- Port 8081 - 伺服器端口,後續要過濾來自這個端口的封包
Step 3: 提取 TCP 流數據
為什麼只提取伺服器端的封包?
TCP 是雙向通訊:
- 客戶端 → 伺服器: HTTP 請求(已經看過了,只有 402 bytes)
- 伺服器 → 客戶端: HTTP 回應 + 影片數據(這才是我們要的!)
如果不過濾,會混入客戶端的 ACK 封包和請求數據,導致提取的檔案損壞。
提取命令
tshark -r security-footage-1648933966395.pcap -Y "tcp.stream eq 0 and tcp.srcport eq 8081" -T fields -e tcp.payload | xxd -r -p > recovered_video.bin命令解析
| 參數 | 說明 |
|---|---|
-Y "tcp.stream eq 0" |
只看 TCP stream 0(我們的 HTTP 連線) |
tcp.srcport eq 8081 |
只取來自伺服器的封包(過濾掉客戶端) |
-T fields -e tcp.payload |
以欄位格式輸出,只提取 TCP |
xxd -r -p |
將十六進位轉回二進位數據 |
結果
ls -lh recovered_video.bin
# -rwxrwxrwx 1 user user 5.7M recovered_video.bin
成功提取 5.96 MB 數據!
Step 4: 檔案格式識別
檢查檔案頭(Magic Bytes)
xxd recovered_video.bin | head -20
發現的內容
00000000: 4854 5450 2f31 2e31 2032 3030 204f 4b0d HTTP/1.1 200 OK.
00000010: 0a43 6f6e 6e65 6374 696f 6e3a 204b 6565 .Connection: Kee
...
00000050: 653a 206d 756c 7469 7061 7274 2f78 2d6d e: multipart/x-m
00000060: 6978 6564 2d72 6570 6c61 6365 3b20 626f ixed-replace; bo
00000070: 756e 6461 7279 3d42 6f75 6e64 6172 7953 undary=BoundaryS
...
000000d0: 7065 3a20 696d 6167 652f 6a70 6567 0d0a pe: image/jpeg..
...
000000f0: 2020 2020 3130 3432 370d 0a0d 0aff d8ff 10427.......
00000100: e000 104a 4649 4600 0101 0000 0100 0100 ...JFIF.........
關鍵發現 🎥
HTTP/1.1 200 OK- 完整的 HTTP 回應Content-Type: multipart/x-mixed-replace- 這是 MJPEG 串流!boundary=BoundaryString- 使用--BoundaryString分隔每一幀Content-type: image/jpeg- 每一幀都是 JPEG 圖片FF D8 FF E0 ... JFIF(offset 0xF0) - JPEG 檔案簽名
什麼是 MJPEG?
Motion JPEG (MJPEG) = 將多張 JPEG 圖片連續串流,形成"影片"
- 監控攝像頭常用格式
- 每一幀都是獨立的 JPEG 圖片
- 適合低延遲即時串流
Step 5: 移除 HTTP Headers
為什麼要移除?
- HTTP headers 不是影片數據的一部分
- 會干擾後續的圖片提取
- 需要找到第一個 JPEG 的起始位置(
FF D8 FF)
方法 1: 使用 grep 定位
tail -c +$(grep -oba $'\xff\xd8\xff' recovered_video.bin | head -1 | cut -d: -f1) \
recovered_video.bin > video.mjpeg
驗證檔案開頭
xxd video.mjpeg | head -5
00000000: 0aff d8ff e000 104a 4649 4600 0101 0000 .......JFIF.....
發現開頭還有一個多餘的換行符 0a(HTTP chunked encoding 的殘留)
方法 2: 再次清理
tail -c +2 video.mjpeg > video_clean.mjpeg
驗證最終結果
xxd video_clean.mjpeg | head -3
00000000: ffd8 ffe0 0010 4a46 4946 0001 0100 0001 ......JFIF......
00000010: 0001 0000 ffe1 0080 4578 6966 0000 4d4d ........Exif..MM
00000020: 002a 0000 0008 0003 0132 0002 0000 0014 .*.......2......
✅ 完美!開頭直接是 JPEG magic bytes FF D8 FF E0
Step 6: 提取所有 JPEG 幀
使用 Foremost
foremost -t jpeg -i video_clean.mjpeg -o extracted_frames
Foremost 工作原理
- 掃描整個檔案,尋找 JPEG 的開始(
FF D8)和結束(FF D9)標記 - 自動分割並提取每一幀
結果
cd extracted_frames/jpg
ls -1
提取出大量 JPEG 檔案,按編號排序:
00000060.jpg
00001307.jpg
00002602.jpg
...
00010898.jpg
Step 7: 組合 Flag
查看圖片內容
每張圖片顯示一個手機螢幕,上面有紅色的十六進位字串!
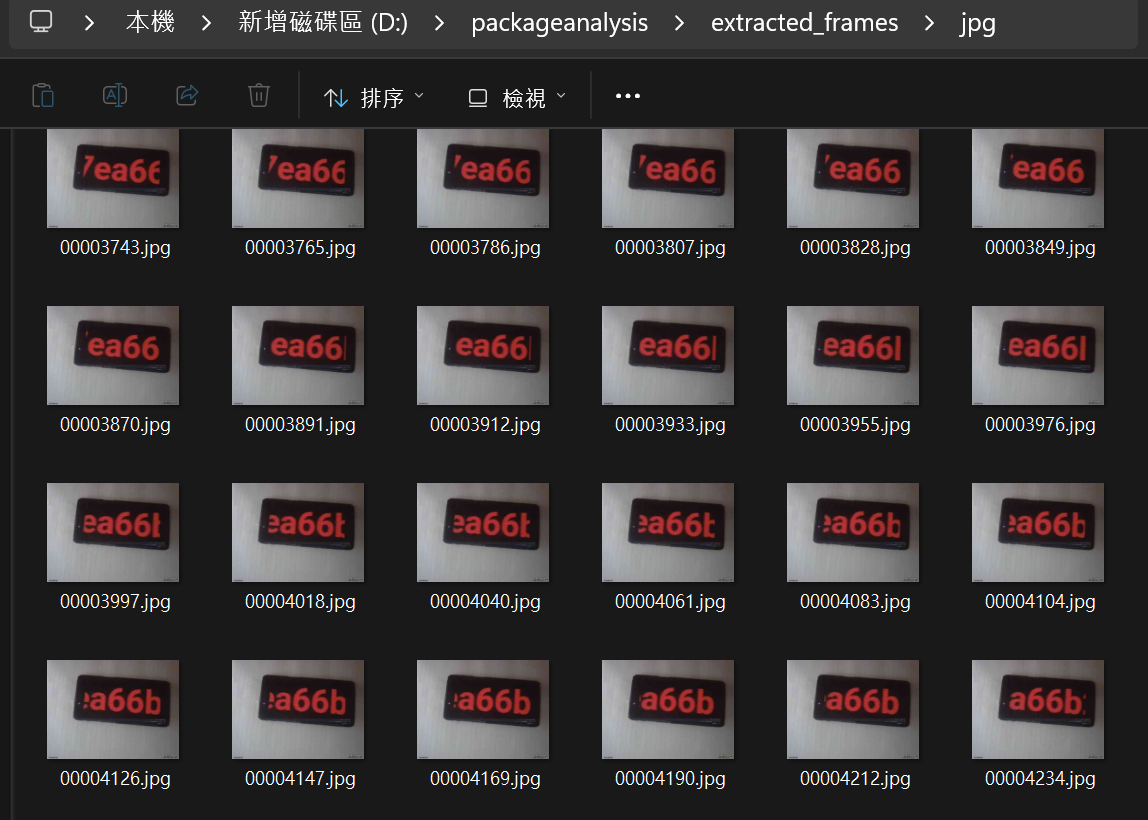
按順序組合
| 檔案 | 內容 |
|---|---|
| 00000060.jpg | flag{ |
| 00001307.jpg | 5eb |
| 00002602.jpg | f457 |
| 00003912.jpg | ea66 |
| 00005605.jpg | b287 |
| 00006902.jpg | 7fdb |
| 00008217.jpg | ca2d |
| 00009565.jpg | e9ec |
| 00010898.jpg | 86f31} |
最終 Flag
flag{Redacted}
技術要點總結
1. 封包分析的流程
1. 協議統計 → 了解整體結構
2. 異常識別 → 找出關鍵線索
3. 深度分析 → 提取關鍵封包詳細資訊
4. 數據重組 → 提取並重建原始檔案
5. 格式識別 → 分析檔案類型
6. 內容提取 → 恢復最終數據
2. 為什麼 HTTP 是關鍵?
- 在大量 TCP 流量中,HTTP 封包提供了上下文
- 告訴我們通訊的目的、方向、內容類型
- 是理解整個資料流的入口點
Member discussion